Customizing cuckoo to fit your needs
With the talk of the .4 release of cuckoo to be publicly released shortly I figured I should get this post out as some of the things I talk about here are said to be addressed and included in that release. If you don’t want to wait for that release or something I touch on here isn’t included in that release then hopefully the information below will be of use to you.
In full disclosure, I’m not a python guru so if you see something that could have been done an easier way or something turns out not to be working for you please let me know…I found out the hard way python is strict on spacing. Throughout my testing it all seemed to work fine for me but there may be some scenario I didn’t test or think of.
(patches available on my github)
General Notes
The installation notes are pretty straightforward to get you up and running and after you successfully do it the first time, any subsequent installation process should be even faster for you. There are a couple of notes worth mentioning though:
- The first user you create during your Ubuntu installation is an admin user. This is important to remember if you want your cuckoo user to be a limited user.
- When you add the cuckoo user to its group, you need to log out and log back in for it to take affect.
- To ensure there are no permission issues, you should do the virtualbox setup as the cuckoo user instead of another admin/root account.
- If during your analysis the VM isn’t able to be restored or you need to kill cuckoo.py then you need to run
virtualboxafter and take the vm our of ‘saved’ mode by discarding it. - If you are installing 3rd party applications (and you should be if you want to test exploitation), make sure you’re properly pointed to them within their appropriate analyzer file “/path/to/cuckoo/setup/packages”
- There’s a default list of hashes for common programs that are automatically discarded in the dropped files section so be aware of them “/path/to/cuckoo/shares/setup/conf/analyzer.conf”
Patching
Instead of re-posting all of the files in the cuckoo repo I decided the easiest way to go about releasing these patches/modifications was to utilize the diff & patch commands in *nix. To create the patches:
diff -u 'original' 'new' > 'file.patch'
and once the patches are downloaded from my github, all you need to do is run:
patch '/path/to/original/cuckoo/file' < 'file.patch'
Customizations
Web Reports/Portal
At first I couldn’t understand why I was able to continuously reanalyze a sample but when I thought about it , it made sense. Since cuckoo gives you the ability to analyze a file in multiple VM’s, it has to be processed more than once (duh)…maybe a better approach would be to only have that sample be analyzed once by the same VM.
In the main web portal page you are presented with a single search box to search for a files MD5 hash. For convenience and as a time saver I hyper-linked the files MD5 hash in the general information section as well as the dropped files section so you can quickly see if/when it was analyzed previously instead of having to copy and paste it in the main search box every time.
I didn’t want to clutter up the general information section of the report with all of the scans and lookups I was adding to the report so I created two other sections for the report (signatures & lookups).
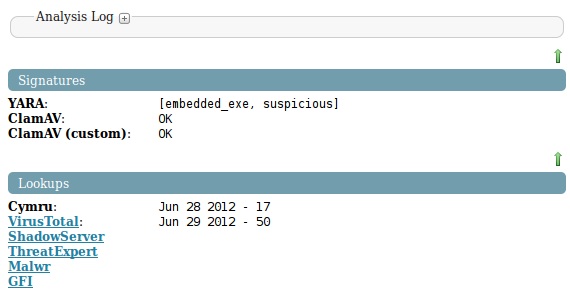
Signatures
Within the signatures section I added the following ClamAV (2 versions) and YARA. If you have other scan engines you wish to run against your files then the same type of method could be re-used. With all three of these features you need to configure the location to their corresponding signatures within “/path/to/cuckoo/processing/file.py”.
ClamAV
besides for above noted change, you also need to edit the path to your clamscan
I’m a fan of ClamAV and the numerous ways it can be leveraged just make it ideal to have included in my automated processes. If you’ve read the Malware Analysts Cookbook (MACB) you might recall that there’s some really handy code made available and one of which shows how to do exactly what I wanted to do – scan the files with ClamAV and show the results. I don’t like to re-do what someone else has done if it works how I need it to so I made one or two modifications and plugged it in as necessary.
Custom ClamAV
Using the traditional signatures database from ClamAV is good but it can also be worthwhile to create some of your own signatures (remember how logical signatures can be a big help) so I also added a section where you can point it to your custom ClamAV database so it can pickup on other signatures you’ve personally written/acquired.
YARA
On the cuckoo mailing list I came across another user who said he had patches for implementing YARA into cuckoo. If you’ve read any of my past posts or follow me on twitter you’ll know that I’m a fan of YARA’s capabilities and as such contacted him to see what he had wrote. The patches themselves were very straightforward and since they worked I didn’t see a need to change them.
He provided me a link to them on his personal GDrive so if you only want to implement that feature into cuckoo then you can use his files, however, the files I’m releasing have that already implemented so no need to do double the work otherwise. When/if more than one YARA rule is matched, they’ll be comma separated within brackets. The additional files needed besides for for the ones in my github that you’ll need to download and install are:
- http://yara-project.googlecode.com/files/yara-1.6.tar.gz
- http://yara-project.googlecode.com/files/yara-python-1.6.tar.gz
Lookups
The looksups section only contains two actual lookups at the moment but also contains what I refer to as ‘future linkage’. I didn’t add the lookups section to the dropped files section because I plan on analyzing them automatically with the modifications mentioned earlier and that would just be too repetitive and a waste of a time. As far as actual lookups I put in Cymru and VirusTotal for right now so if there’s Internet they will pull the last time the sample was scanned/seen with their services and the A/V detection rate.
Note: I’m only querying for the hashes, I don’t like submitting for a few reasons
Team Cymru
Team Cymru offers a couple of very useful services and one of which I use during investigations is their Malware Hash Registry (MHR). MHR will take the hash(es) you supply it and tells you if it’s a known bad file, the last time they’ve seen it and an approximate percentage for A/V detection. MACB also had a recipe for adding this to a script so once again I just modified as necessary and inserted to fit cuckoo.
VirusTotal
There are a few scripts online to utilize VirusTotals API and submit/query their site but I decided to use this script. You can use any method you’d like but if you use the patches I provided just install that script and supply your API key in “/path/to/cuckoo/processing/file.py”.
I didn’t want to overly insert code into the existing cuckoo files so I opted to build this file and then import it from within cuckoo. Essentially I take the files hash and try to get a report of it and if it exists just pull last scan date and detection rate. While it can be useful to see what the A/V’s detected it as, I didn’t want to waste time making a collapsable table including all of this information if the new release of cuckoo will already do this. If it doesn’t, then I’ll re-visit it.
If the sample doesn’t have any VT detection or exist then I have it just state that and if there’s no current Internet connection then state an error. The latter is very important because I’ve seen others trying to stuff this capability into their code but they fail to address the scenario when there’s no Internet connectivity and therefore their report will fail to be created because they don’t handle the error created.
I wrote it so it would be generic in catching an error because I don’t want my report to fail because of this so if there’s no Internet connection or another error (note that this will also suppress the error that your API key may be wrong!) and the rest of the report is fine to generate then it can still generate. The same hold true for the snippet for the Cymru check.
| Description | Example |
|---|---|
| Internet connection and results found | 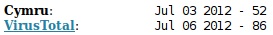 |
| No Internet connection |  |
| Internet connection and no results found |  |
Future Linkage
I thought it was useful to pre-link the samples to common online sites people use for additional reference/analysis (malwr, shadowserver and threatexpert). Instead of slowing up the analysis by trying to pull down all of these reports if they exists then parse them I decided it was just easier to create a link for them based on the samples hash that way even if the sample hasn’t been analyzed on any of these sites at the time of my analysis, I could go back to them at a later time and check if a report exists since then. Just another way to save some time and make life easier.
Dropped Files
Cuckoo will take any dropped files during the analysis of the sample and copy them back over to the host machine under the structure “/path/to/cuckoo/analysis/<#>/files”. By default those files are just left in that subfolder and not analyzed (they will have basic information such as file type and hash in the report though) but I felt it didn’t make sense to just leave them in that sub-directory (at least for my goals) so I added the following opted to change “/path/to/cuckoo/processing/data.py” so it would take those files and move it to my samples directory (/opt/samples):
shutil.move(cur_path,'/opt/samples')
This samples folder is the folder that I’m going to monitoring for new/created files and automatically process them to be analyzed as mentioned later via the watcher.rb script. Once I did that I noticed another side affect… if there was a queue in the samples directory and the files being moved from the dropped files folder to the samples folder were the same then it would crap out. I thought the move command would overwrite it but it didn’t. I figured this could be fixed by either copying instead or what I chose to do, check if it exists and if so just delete it from the dropped files folder since it was going to be processed anyway:
check = os.path.join('/opt/samples/', cur_file)
if os.path.exists(check):
os.remove(cur_path)
else:
shutil.copy(cur_path,'/opt/samples')
os.remove(cur_path)
return dropped
This may not be something that everyone feels they want to do since one obvious consequent I could think of was that since every file is being moved out of the dropped files directory, any special configuration file etc. that you might be interested in won’t be there (unless you do file type identification and only move files which can even be processed or if a file can’t be processed, move it out of the samples directory to another folder to store dropped files that couldn’t get processed e.g. - html files, js etc.).
Another reason might be because it may end up being a continual loop. Some malware will go out and download another copy of itself etc. and as such by continuing to automatically analyze them will just cause a loop. This will vary of course by sample, if the Internet is connected and what you want out of your analysis. Other than that, your analysis task numbers might rise quickly but that shouldn’t be on concern because you aren’t going to have a sequential set since there’s going to be times when a file can’t be processes.
Samples Directory Watcher
Melissa wrote a post a little bit ago on integrating cuckoo with NTR and in that post she touched upon the usefulness of having a script running to automatically realize that a new file was created or moved to a certain directory and then take action on that file. I thought it was nifty and since it was already built into Ruby, I wasn’t going to try and hack something else together and see how it held up.
I’ve read that INotify can be a memory hog so that’s something that should be paid attention to although I haven’t had any noticeable issues thus far. If you read the original post you’ll soon realize there’s some typos… Melissa pointed one out but there are a couple others that might make you frustrated when troubleshooting and to make things easier, I took care of them already. To get this directory watcher up and running do the following:
sudo apt-get install ruby rubygems
sudo gem install rb-inotify
Download the modified watcher.rb script (on my github too) and edit it to point to the directory you want to watch and the script you want it to execute upon an action/event occurring. Instead of having an interim script here you can just pass the new sample to “/path/to/cuckoo/submit.py” but I realized I needed an interim script because the sample might be password protected or in a format that cuckoo wouldn’t take (e.g. - an archive file).
That’s the basic customization you need to do for this script, however, you can change it as you see fit. Initially when I was talking to some Ruby gurus they said that using the IO.popen method was overhaul for what I wanted to do since all I’m essentially doing is passing along a string (new file created/moved) to another file to process. For testing purposes, I changed it to use exec instead… which worked, but would kill the watcher script after each event…. and that basically killed the purpose of me even having it running so I opted to keep the original method. Once you have all of the pre-reqs installed and the script modified to your needs just open another tab in your shell and let it fly (you don’t need the ‘&’ at the end but I like to get my terminal back):
ruby watcher.rb
Archive Parser
If you’re like me then you might have some emails which contain malware samples as attachments or download/get sent password protected archives with possible malware. If you hand cuckoo an archive or email file (pst etc.) then nothing will happen as it doesn’t have a default module to handle them. As far as the email situation goes, the sheer thought of individually saving each sample one by one doesn’t sound like fun so figured within the interim script I’m calling from the watcher script that there would be a check for a Microsoft Outlook data file and if so, run pffexport against the file. The thought process is to basically just recursively extract everything out of the the email messages and attempt to process them with cuckoo.
if you install
libpff, remember tosudo ldconfigafter you install it
To address the archives/pw protected archives issue I try to identify it as an archive file and if so, try to unzip it both with and without a password. I wasn’t aware that if you supply a wrong password to unzip a file with 7zip that it will still unzip the archive if it turns out that there isn’t even a password protecting the archive (thanks Pär). I also have a little array set up which contains some of the common password schemes used to password protected malware archives that way I could also add to it in the future (sort of like a dictionary).
Additional Software
Depending on the installation you’re performing and what additional features you’re going to be installing there might be some additional software required which could include:
| Software | How to get it |
|---|---|
| YARA | sudo apt-get install libpcre3 libpcre3-dev |
| python | sudo apt-get install python python2.7-dev python-magic python-dpkt python-mako |
| ssdeep/pyssdeep | http://sourceforge.net/projects/ssdeep/files/ssdeep-2.8/ssdeep-2.8.tar.gz/download , svn checkout http://pyssdeep.googlecode.com/svn/trunk/ pyssdeep |
| g++ | sudo apt-get install g++ |
| subversion | sudo apt-get install subversion |
| 7zip | sudo apt-get install p7zip |
To-Do & Wishlist
- The cuckoo DB that’s created “/path/to/cuckoo/db/cuckoo.db” only stores a limited amount of information within it. Even though information regarding a files SHA1/256 hash, ssdeep hash, mutexes, IP/domains etc. are included in the samples report, they aren’t stored in the DB. This helps keep the DB to a limited size but doesn’t help if I want to search my repository of analyzed samples for all samples which called a particular IP/host etc. I didn’t want to start changing big chunks of the code to implement this at this point because updates may kill it etc… so I think the better solution will be to only change the snippet which says which fields to create in the DB and to store other selected fields into that DB after analysis. Another solution can be used to query that DB as it’s a common task many of us do anyway.
- The file identification process for determine what type of file the sample is and if it should be processed is pretty basic at this point. It does the job but at times could use a boost. A similar thing noticed is if there’s certain characters in the samples file name then it won’t get processed. This looks like it could be a one or two line fix with something like Python’s string.printable .
- After talking with one of my friends about cuckoo he noted that he’s observed not all of the dropped files from the sample being analyzed were being copied back over to the host after the analysis. This is no bueno… and while I haven’t verified this at this time, a simple solution looks to be installing
CaptureBATon the Windows VM and using something (xcopy or robocopy) to copy all of the files caught by CaptureBAT back over to the host after analysis. - I’m debating to add a switch so I can choose for the analysis to either run wild on the Internet or feed it something like
INetSimfor simulation. There are pros and cons to each scenario and maybe a better solution is to use something like Tor … but I’m up in the air. As a side note, installing INetSim can be a pain and I’m spoiled as I’m used to it already being installed so other options to look at could be something likeHoneyD. - I’d like to modify some of the existing analyzers to run additional programs against a sample and report on their results (e.g. -
hachoir-subfile,pdfextractetc.)