Getting what you want out of a PDF with REMnux
I was talking recently with a coworker who brought up the fact that she was having a problem extracting something from a PDF. It was cheating a little bit since we knew there was definitely something there to extract and look for because of another analysis previously posted. When I read a post about someone doing an analysis I always like when they show a little more details about how they got to the end result and not just showing the end result - and this was a case of the latter. As a result of this little exercise I thought I would write a quick post on how to do the same type of thing with the CVE-2010-0188 shown here.
I know there’s a wealth of write ups for analyzing PDF’s but only a handful are solely done in REMnux and they don’t always show multiple ways to get the job done. I have no problem analyzing on a Windows system with something like PDF Stream Dumper (love the new JS UI) but the fact that REMnux is so feature and tool packed makes it possible to solely stick within its environment to tackle your analysis if need be.
One of the first things I run on any file I’m analyzing is hachoir-subfile. There’s other tools within this suite which are also useful but this one isn’t necessarily file type specific so it’s a great tool to run during your analysis and see if you can get any hits… unfortunately, I didn’t get any in this instance.
Method 1
Most of you are probably familiar with pdfxray and while the full power of it isn’t within REMnux, there’s still a slimmed down version, pdfxray_lite, which can provide you an easy to view overview of the PDF.
pdfxray_lite
pdfxray_lite -f file.pdf -r rpt_

No, that’s not a typo in the report name, I added the “_” so that it would be separated from the default text added to the report name which is its MD5 hash. If we take a look at the HTML report in Firefox Object 122 stands out as being sketchy. It looks to contain an /EmbeddedFile and the decoded stream looks like it’s Base64 encoded:
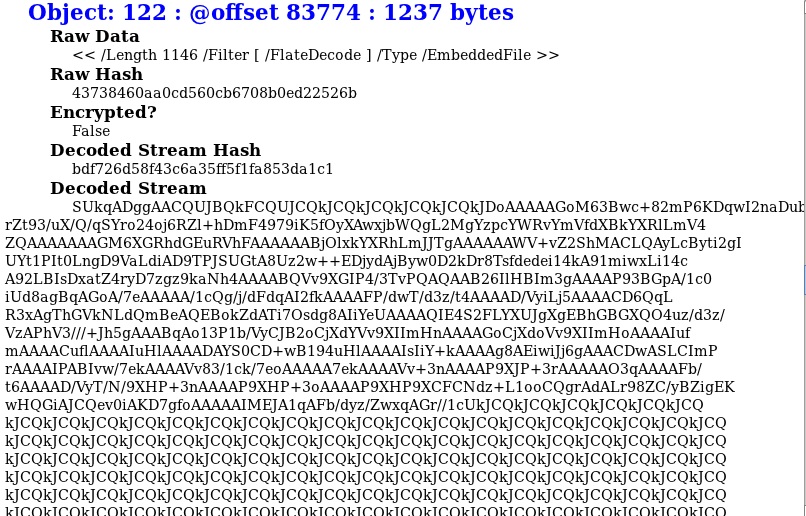
the repeated characters seen above also resemble a NOP sled
pdfextract
Another one of my favorites is pdfextract from the Origami Framework as it can also extract various data such as streams, scripts, image, fonts, metadata, attachments etc. It’s nice sometimes to have something just go and do the heavy lifting for you but even if you don’t get what you wanted extracted, you still might get some other useful information:
pdfextract file.pdf
The above command results in a directory named ‘
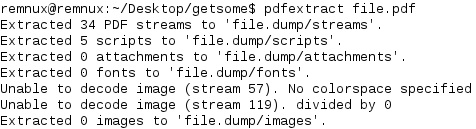
Now.. we’re after a TIFF file in this case but still even this tool doesn’t seem to have extracted it for us… something unusual must be going on since the above two tools are great for this type of task 9 times out of 10. In this particular instance, if we list the contents of this dump directory we can see ‘script_
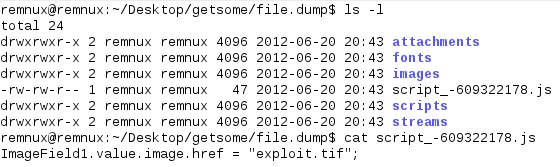
Looks like there was something in the PDF referencing an image field linked to ‘exploit.tif’. People get lazy with their naming conventions or sometimes even just copy stuff that’s obvious (check @nullandnull ‘s slides as he talks more about this trend.). Since we don’t have any extracted images we can check out the contents of the other files extracted. Pdfxray_lite gave us a starting point so let’s dig deeper into Object 122 and check out it’s extracted stream from pdfextract:
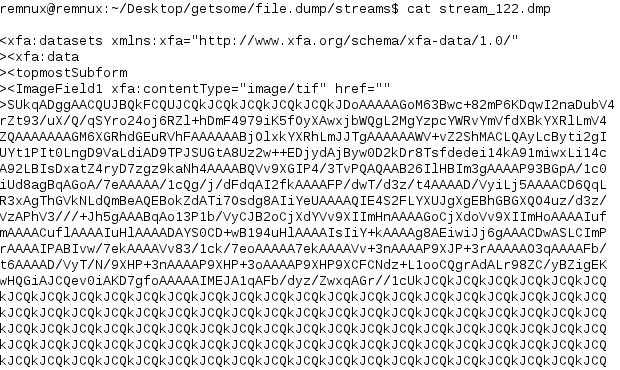
Hm… the content type is ‘image/tif’ and the HREF link looks empty followed by a blog of Base64 encoded data. There’s online resources to decode Base64, or maybe you’ve written something yourself, but in a pinch it’s nice to know REMnux has this built it by default with the base64 command. If you just try:
base64 -d stream_122.dmp > decoded_file
you’ll get an error stating “base64: invalid input”. You need to edit that file to only contain the Base64 data. I popped it into vi and edited it so the file started like so:

and ended like this:

Now that we got the other junk out of the file we can re-run the previous command :
base64 -d stream_122.dmp > decoded_file
and if we do a ‘file’ on the ‘decoded_file’ we see we now have a TIFF image:
file decoded_file

To see if it matches what we saw in the other analysis we can take a look at it through ‘xxd’ :
xxd decoded_file | less

The top of the file matches and shows some if its commands and the bottom shows the NOP sled in the middle down to those *nix commands:

Method 2
Lenny had a good write up on using peepdf to analyze PDF and its latest release added a couple of other handy features. Peepdf gives you the ability to quickly interact with the PDF and pull out information or perform the tasks that you are probably seeking to accomplish all within itself. It’s stated that you can script it by supplying a file with the commands you want to run … and why that might be good for somethings like general information I found it difficult to be able to do that for what I was trying to do. Mainly, on a massive scale I would have to know exactly what I wanted to do on every file and that’s not always the case as is with this example.
peepdf
To enter its interactive console type:
peepdf -i file.pdf
This will drop you into peepdf’s interactive mode and display info about the pdf:

The latest version of peepdf also states there’s a new way to redirect the console output but since I was working on a back version on REMnux I just changed the output log. This essentially “tee’s” the output from whatever I do within the peepdf console to STDOUT and to the log file I set it to:
PPDF> show output output = "stdout" PPDF> set output file 122.txt PPDF> show output output = "file" fileName = "122.txt"
You may not need do the above step in all of your situations but I did it for a certain reason which I’ll get to in a minute… Since we already know from previous tools that object 122 needs some attention we can issue object 122 from within peepdf which will display the objects contents after being decoded/decrypted:
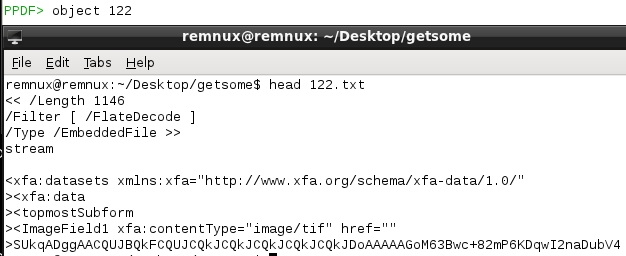
The top part of the screenshot is the command and the second half of the screenshot is another shell showing the logged output of that command which was sent to what I set my output log to (122.txt) previously. We already saw that we could use the built in base64 command in REMnux to decode our stream but I wanted to highlight that you can do it within peepdf as well with one of its many commands, decode.
This command enables you to decode variables, offsets or files. Since we logged the content of object 122 to a file we can use this filter from within peepdf’s console - I wasn’t able to do it all within the console (someone else may shed some light on what I missed?) but I believe it’s the same situation where you need to remove the junk other than what you want to Base64 decode. As such, if I just opened another shell and vi’ed the output log (122.txt) to only contain the base64 encoded data like we did earlier then I could issue the following from within peepdf:
set output file decoded.txt
decode file 122.txt b64
The above commands change the output log file of peepdf to “decoded.txt” and then tells peepdf to decode that file by using the base64/b64 filter:
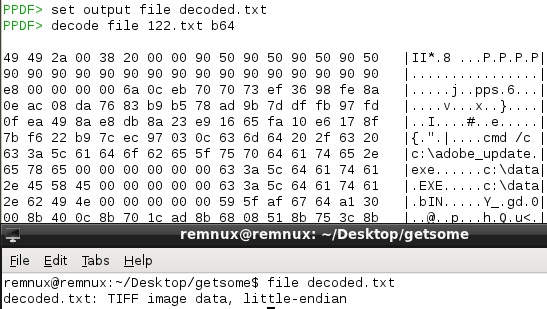
I can once again verify my file in another shell with:
file decoded.txt
which as you can see in the bottom half of the above screenshot shows it’s a TIFF image.
I’ve only outlined a few of the many tools within REMnux and touched on some of their many individual features but if you haven’t had the time to or never knew of REMnux before I urge you to start utilizing it. Peepdf alone has a ton of other really great features for xoring, decoding, shell code analysis and JS analysis and there are other general tools like pdfid & pdf-parser but it’s important to know what tools are available to you and what you can expect from them.