What's in your logs?
I’ve had this on the back burner for a few months but I’m finally getting around to writing up a post about it. I re-tested the scenarios listed below with log2timeline v0.63 in SIFT v2.12 and verified it’s still applicable.
The Scenario
I was investigating an image of a web server which was thought to have some data exfiltrated yada yada.. Log analysis was going to be a key part of this investigation and I had gigs to sift through.
Among a few other tools, I ran the logs through log2timeline and received my timeline - or so I thought. There wasn’t any indication that entire files couldn’t be parsed or files that were skipped in the STDOUT so one would assume everything was successful- right? Not so much. I don’t like to stick to one tool and this wasn’t going to be any different. I loaded the logs with a few other tools (Notepad++, Highlighter, Splunk, Bash etc.) and verified my results. As a result of being thorough, I noticed that there were a bunch of lines from the apache2 error logs which were present in the other tools outputs but were noticeably missing in my timeline. After some digging around and some additional testing with sample data sets I noticed there were a few problems.
The Problems
Parser error via regex processing
The apache2_error parser says it has to match the regex of Apache’s defined format or log2timeline won’t process it:
# DOW month day hour min sec year level ip message
# ^\[[^\s]+ (\w\w\w) (\d\d) (\d\d):(\d\d):(\d\d) (\d\d\d\d)\] \[([^\]]+)\] (\[([^\]]+)\])? (.*)$
#print "parsing line\n";
if ($line =~ /^\[[^\s]+ (\w\w\w) (\d\d) (\d\d):(\d\d):(\d\d) (\d\d\d\d)\] \[([^\]]+)\] (\[([^\]]+)\]) (.*)$/ )
{
$li{'month'} = lc($1);
$li{'day'} = $2;
$li{'hour'} = $3;
$li{'min'} = $4;
$li{'sec'} = $5;
$li{'year'} = $6;
$li{'severity'} = $7;
$li{'client'} = $8;
$li{'message'} = $10;
if ($li{'client'} =~ /client ([0-9\.]+)/)
{
$li{'c-ip'} = $1;
}
}
elsif ($line =~ /^\[[^\s]+ (\w\w\w) (\d\d) (\d\d):(\d\d):(\d\d) (\d\d\d\d)\] \[([^\]]+)\] (.*)$/ )
{
$li{'month'} = lc($1);
$li{'day'} = $2;
$li{'hour'} = $3;
$li{'min'} = $4;
$li{'sec'} = $5;
$li{'year'} = $6;
$li{'severity'} = $7;
$li{'message'} = $8;
}
else
{
print STDERR "Error, not correct structure ($line)\n";
return;
}
…so why some of the lines in the logs followed it, it was later noticed that others were far from the required standard and resulted in a loss of data being produced. Examples of what I mean are :
cat: /etc/passwrd: No such file or directory
find: `../etc/shadow': Permission denied
As shown above, some of the logs were errors, permission denied statements etc. as a result of the external actor trying to issue commands via his shell (obviously not fitting the standard format). Once I noticed not all of the lines were being parsed I checked what else this parser required to be a valid line and did a quick sed on the fly and found any log entry that didn’t match the requested format and added a dumby beginning (date, time etc.) so it would at least parse everything.
This could have been done in many ways, with other regex’s etc. but for this example I just wanted a quick look to see exactly how many lines in the files didn’t adhere to the standard format so I did it this way:
hehe@SIFT : cat error.log | grep "^\[" > error.log.fixed
hehe@SIFT : cat error.log | grep -v "^\[" > problems.txt
hehe@SIFT : cat problems.txt | sed 's/^/[Fri Dec 25 02:24:08 2010] [error] [client log problem] /' >> error.log.fixed
It was a quick hack, but not an ultimate solution.
Skipping valid lines when invalid lines exist
Even though some of the files didn’t contain valid lines, some of them were completely fine but yet still to my surprise, they weren’t parsed. It seemed that if certain lines existed within the logs that they wouldn’t get parsed … maybe even the possibility that at some point log2timeline would just skip the rest of the files and not try to parse them at all :/
Testing
Here’s an example of the type of data I used for the re-testing:
| File | Test Line |
|---|---|
| error_fail.log | cat: /etc/passwrd: No such file or directory |
| error_fail.log | find: ` ../etc/shadow’: Permission denied ` |
| error_mix.log | [Fri Dec 25 02:24:08 2010] [error] [client 1.2.3.4] File does not exist: /var/www/favicon.ico |
| error_mix.log | cat: /etc/passwrd: No such file or directory |
| error_mix.log | find: `../etc/shadow’: Permission denied |
| error_mix.log | Fri Dec 30 02:24:08 2010] [error] [client 1.2.3.4] File does not exist: /var/www/favicon.ico |
| error_ok.log | [Fri Dec 23 02:24:08 2010] [error] [client 1.2.3.4] File does not exist: /var/www/favicon.ico |
| error_ok2.log | [Fri Dec 24 02:24:08 2010] [error] [client 1.2.3.4] File does not exist: /var/www/favicon.ico |
I flip-flopped the number of lines contained in the logs on occasion as well as the dates & order within a single file to test multiple scenarios and to see if certain lines were getting parsed.
Processing multiple files
So here are two files, both containing all valid lines:
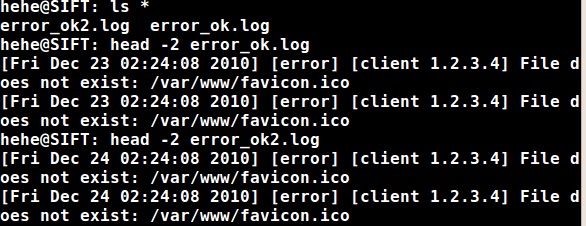
So let’s try saying “*.log” for the file to be parsed:
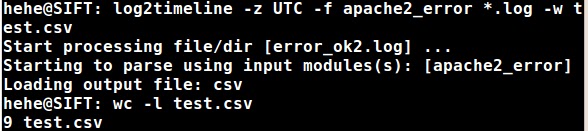
…but by doing that log2timeline will only take the first file and skip everything else as the above image shows. I’ll admit that fooled me for a bit, I thought it would work.
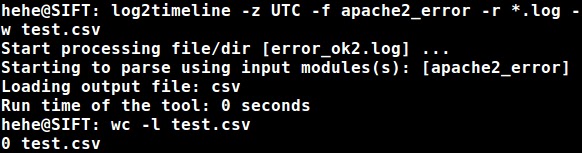
If you supply the (-r) option you can’t supply *.log as it’ll result in an empty file (yes, I deleted the test.csv prior):
However, if you supply the (-r) option with a directory (i.e. $PWD) it will try to parse everything & tell you what files it can’t open. It will also tell you if a logs line couldn’t be processed, however, it doesn’t tell you from what file (if there’s multiple being processed) :
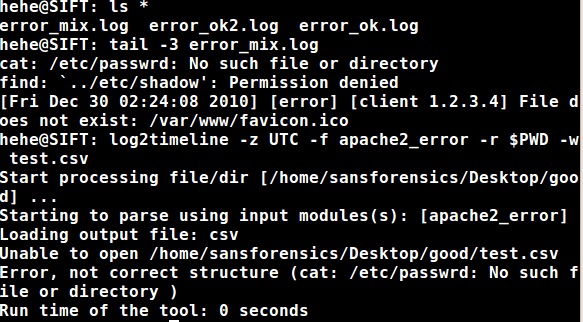
and it also doesn’t state that it stopped and didn’t continue parsing - If you look above, the error_mix.log had a date of 12/30/2010 after its invalid lines which doesn’t end up in our results …whoops:
hehe@SIFT: cat test.csv | awk '{print $1}' | sort | uniq -c
8 12/23/2010,02:24:08,UTC,MACB,apache2_error,Apache2
8 12/24/2010,02:24:08,UTC,MACB,apache2_error,Apache2
5 12/25/2010,02:24:08,UTC,MACB,apache2_error,Apache2
1 date,time,timezone,MACB,source,sourcetype,type,user,host,short,desc,version,filename,inode,notes,format,extra
So it looks like if there’s an invalid line within a log being parsed that log2timeline will stop processing that file? :/ … not much indication of that unless we already know what’s in our data set being parsed.
Right about now some of you are saying… hey man, there’s a verbose switch. Correct, there is. And while it’s helpful to tackle some of the things I’ve mentioned, it still isn’t the savior. When I ran the following:
hehe@SIFT: log2timeline -z UTC -f apache2_error -v -r $PWD -w test_verbose.csv
I received this to STDOUT:
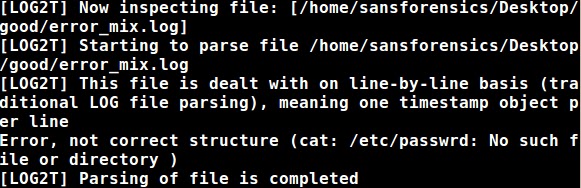
So the verbose switch told me it was processing the file, that it didn’t like a line within the file and that it finished processing this file… but it still didn’t process the entire error_mixed.log file again:
hehe@SIFT: cat test_verbose.csv | awk '{print $1}' | sort | uniq -c
8 12/23/2010,02:24:08,UTC,MACB,apache2_error,Apache2
8 12/24/2010,02:24:08,UTC,MACB,apache2_error,Apache2
5 12/25/2010,02:24:08,UTC,MACB,apache2_error,Apache2
1 date,time,timezone,MACB,source,sourcetype,type,user,host,short,desc,version,filename,inode,notes,format,extra
(same held true for very verbose)
Now it’s possible that this has something to do with the amount of lines that are read to determine if there’s an actual Apache2 error log base :
# defines the maximum amount of lines that we read until we determine that we do not have a Apache2 error file
my $max = 15;
my $i = 0;
But if that were the case I thought I’d see an error like this:
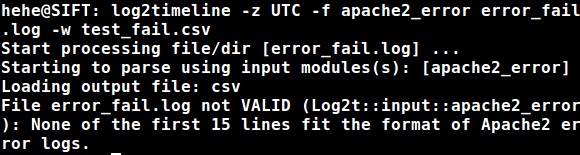
Ok.. so the above STDOUT at least tells us the file trying to be parsed couldn’t because its first 15 lines weren’t valid which goes along with the previously stated snippet about the 15 lines needing to be met. So what happens if we add other files to be parsed in the same directory as that file, same notification?
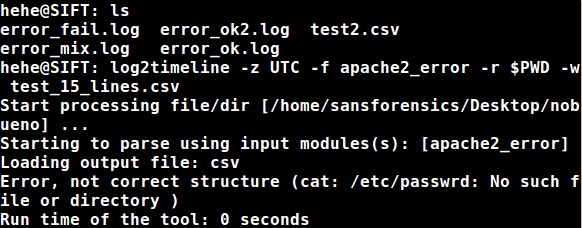
Nope - It appears we don’t get any notification that a file couldn’t be processed but with the (-v) switch on we get this information. So at this point the error_fail.log doesn’t have 15 valid lines so just for troubleshooting purposes I altered the error_mixed.log to contain the following:
(19x) [Fri Dec 25 02:24:08 2010] [error] [client 1.2.3.4] File does not exist: /var/www/favicon.ico cat: /etc/passwrd: No such file or directory
find: `../etc/shadow': Permission denied (15x) [Fri Dec 30 02:24:08 2010] [error] [client 1.2.3.4] File does not exist: /var/www/favicon.ico
This data set would suffice since there are at least 15 valid lines in the beginning of the file to be considered a valid file to parse so let’s try to parse a directory with the new error_mixed.log file and two files with all valid entries (error_ok.log & error_ok2.log):
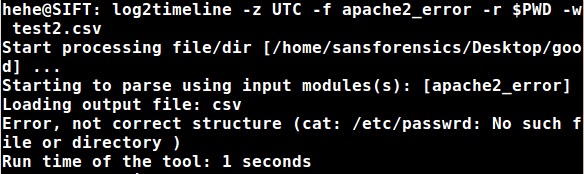
We see again that there was a file that contained an invalid line. In the images below, we see that it appears the error_ok.log (12/23/12) & error_ok2.log (12/24/12) files were parsed but the error_mixed.log (12/25/12,
hehe@SIFT: cat test2.csv | awk '{print $1}' | sort | uniq -c
8 12/23/2010,02:24:08,UTC,MACB,apache2_error,Apache2
8 12/24/2010,02:24:08,UTC,MACB,apache2_error,Apache2
19 12/25/2010,02:24:08,UTC,MACB,apache2_error,Apache2
1 date,time,timezone,MACB,source,sourcetype,type,user,host,short,desc,version,filename,inode,notes,format,extra
Even with the verbose switch on it still didn’t state any indication that it didn’t continue parsing the file or skipped over any other parts of it besides the invalid log it pointed out.
Proposed Solution
I have some ideas of what can be done but I opened an issue ticket so others in the community could chime in as well. I talked with the plugins’ author @williballenthin and provided my test samples & findings and he agreed that there should be some others input into the solution. Here’ what I thought… the ticket has a typo, it was re-tested in SIFT v2.12 (2.13 wasn’t out yet :)
-
Either the first line in the error log has to fit the standard format or one out of the first x lines (right now it’s set to w/in the first 15); If not, spit out an error stating that particular file couldn’t be parsed & continue onto the next log file if there are multiple since the next one may have valid entries.
-
As long as at least one line is found to meet the standard format, once a line is found that doesn’t meet the standard format after that (e.g. doesn’t start with [DOW month …]) then copy that information from the line before it (with the valid format/timestamp) and add it to the beginning so it meets the format and can be put into the timeline of events.
Conclusion
So why did I write all this up and why do you care? Log2timeline is purely awesome. It’s changed many aspects of DFIR but there’s always going to be improvements needed. It’s open source and for the community so the feedback will only make it better. Someone else may be dealing or have to deal with exactly what you’ve come across so why not make it known?
It’s crucial that you understand how the tools/techniques you’re using work to the best of your ability. If by solely relying on clicking buttons is your method of expertise, you’re gonna get caught at some point. Even though Willi didn’t have these types of examples to test the parser on when he originally created it, I wanted to get this information out there because I fear that there are others who might not have realized what I did.
If I hadn’t checked my timeline against other tools I would have missed key information for this analysis.
Do you double check your results? Are you seeing the whole picture?